
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 스마트포인터
- 선택정렬
- tweakobjectptr
- 델리게이트
- 애셋로드
- C++
- 언리얼가비지컬렉터
- stl
- UE_LOG
- 자료구조
- 프로그래머스
- 알고리즘
- C++최적화
- 크리티컬섹션
- 람다
- UML관련
- BFS
- 정렬
- unorder_map
- 약참조
- 구조적 바인딩
- moreeffectiveC++
- 정렬알고리즘
- dataasset
- 데이터애셋
- enumasByue
- makeweakobjectptr
- map
- 강참조
- 비동기호출방법
- Today
- Total
기억을 위한 기록들
[알고리즘]정렬 알고리즘의 선택과 종류 7가지 본문
- 초안 작성 : 2020년 12월 27일
- 1차 수정 : 2023년 4월 3일
정렬 알고리즘이란?
- 목록 안에 저장된 요소들을 특정한 순서대로 재배치하는 알고리즘
- 입력데이터는 보통 배열과 같은 데이터 구조 (연결리스틑 사용하면 처음 or 끝부터 차례대로 훑어야해서 정렬 시 사용이 복잡해진다)
- 흔히 사용하는 순서 : 숫자 , 사전 순서(A~Z)
- 정렬 방향 : 오름차순, 내림차순
사용하는 이유??
- 좀 더 효율적인 알고리즘을 사용하기 위해
- 사람이 읽기 편함을 위한 등등...
정렬시 고려사항
- 시간 복잡도
- 메모리 사용량
- 안정성(stability) - > safety가 아니라 stable 이다. -> 데이터의 순서가 바뀌지 않느냐 여부 문제
- 직렬 vs 병렬
안정성을 잘 모르는 이유
- "모든 정렬 알고리즘은 같은 키를 가진 데이터의 순서를 안바꾼다"라고 잘못생각함.
모든경우에 대해 최선의 정답을 내는 알고리즘은 없다.
정렬 알고리즘을 선택할때 고려해야할점으로
1. 정렬할 데이터의 양
2. 데이터와 메모리
3. 이미 정렬된 정도
4. 필요한 추가 메모리의 양
5. 상대위치 보존여부(안정성) 등
에따라 선택이 달라질 수 있다.
정렬알고리즘 7가지
1. 선택정렬(Selection Sort)
방법 : 선택된 값과 나머지 데이터중에 비교하여 알맞은 자리를 찾는 알고리즘. 안정성은 보장되지 않는다.
예시:

코드 :
void Select(int arr[],int n)
{
int i,j,min;
for(i = 0;i <n - 1;i++)
{
min = i;
for(j=i+1;j<n;j++)
{
if(arr[j] < arr[min])
{
min=j;
}
}
//스왑은 대충 바꿔주는 함수...
swap(&arr[min], &arr[i]);
}
}//End of Select
- 빅오 표기(시간복잡도)

worst,average,best 모두 동일
2. 삽입정렬(Insertion Sort)
설명 : -데이터 집합을 순회하면서 정렬이 필요한 요소롤 뽑아내어 이를 다시 적당한곳으로 삽입하는 알고리즘.
-성능은 버블정렬보다 좋음
예시 :

코드 :
버전 1.
void InsertionSort(int arr[], int length)
{
int i = 0;
int j = 0;
int key = 0;
for (i = 1; i < length; i++)
{
key = arr[i];
for(int j = i-1;j>=0;j--)
{
if(arr[j]>key)
{
arr[j+1] = arr[j];
}
else
{
break;
}
}
arr[j+1]=key;
}
}
worst,average 동일, best 이미 정렬되어 있다면 O(n)
3. 버블정렬(Bubble Sort)
설명 : 거품이 수면으로 올라오는 듯 하여 붙여진 버블정렬. 인접한 두 수를 비교하여 오름차순or 내림차순. 안정성은 보장한다.
예시 :

코드 :
void BubbleSort(int* _arr, int _length)
{
int i = 0;
int j = 0;
int temp = 0;
for (i = 0; i < _length - 1; i++)
{
for (j = 0; j < _length - 1 - i; j++)
{
if (_arr[j] > _arr[j + 1])
{
temp = _arr[j];
_arr[j] = _arr[j + 1];
_arr[j + 1] = temp;
}
}
}
}
- 빅오 표기(시간복잡도)
worst,average,best 모두 동일
4. 병합 정렬(Merge Sort)
설명 : 둘 이상의 부분집합으로 가르고, 각 부분집합을 정렬한 다음 부분집합들을 다시 정렬된 형태로 합치는 방식. 안정성은 보장한다.
- 분할 정복법 사용(Divide-And-Conquer)
- 분할 : 해결하고자 하는 문제를 작은 크기의 동일한 문제들로 분할한다.
- 정복 : 각각의 작은 문제를 순환적으로 해결한다.
합병 : 작은 문제의 해를 합하여(merge) 원래 문제에 대한 해를 구한다.
예시 :

코드 :
#include<iostream>
using namespace std;
#define ARRNUM 5
int N = ARRNUM;
int arr[] = { 8,5,3,1,6 };
int tempArr[ARRNUM];
void Merge(int left, int right)
{
//절반짜리 arr을 tempArr에복사한다.
for (int i = left; i <= right; i++)
{
tempArr[i] = arr[i];
}
int mid = (left + right) / 2;
int tempLeft = left;
int tempRight = mid+1;
int curIndex = left;
//temparr배열 수횐하. 왼쪽 절반과 오른쪽 절반 비교해서
//더 작은 값을 원래 배열에 복사
while (tempLeft <= mid && tempRight <= right)
{
if (tempArr[tempLeft] <= tempArr[tempRight])
{
arr[curIndex++] = tempArr[tempLeft++];
}
else
{
arr[curIndex++] = tempArr[tempRight++];
}
}
//왼쪽 절반에 남은 원소들을 원래 배열에 복사
int remain = mid - tempLeft;
for (int i = 0; i <= remain; i++)
{
arr[curIndex + i] = tempArr[tempLeft + i];
}
}
void Partition( int left, int right)
{
if (left < right)
{
int mid = (left + right) / 2;
Partition(left, mid);
Partition(mid + 1, right);
Merge(left, right);
}
}
int main() {
Partition(0, N - 1);
for (int i = 0; i < N; i++)
{
cout << arr[i] << endl;
}
return 0;
}- 병합정렬은 다른 대부분의 정렬 알고리즘과 달리 데이터 집합이 메모리에 한번에 올리기에 너무 클때 쓰기 좋은 방법이다. ex. 큰 파일의 내용을 여러개의 작은 파일로 나누어 적당한 알고리즘으로 정렬하고 다시 저장하는 식으로 합치기
- 빅오 표기(시간복잡도)
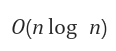
worst,average,best 모두 동일
- 다른 알고리즘과 비교 했을 때 O(n) 수준의 메모리가 추가로 필요하다는 단점
5. 힙 정렬
설명 : 트리 기반으로 최대 힙 트리or 최소 힙 트리를 구성해 정렬을 하는 방법. 안정성 보장 X
내림차순 정렬을 위해서는 최대 힙을 구성하고 오름차순 정렬을 위해서는 최소 힙을 구성하면 된다.
예시 :

- 완전이진트리 여야 함.
- 빅오 표기(시간복잡도)
worst,average,best 모두 동일
6. 퀵 정렬(Quick Sort)(분할정복)
방법 : 데이터 집합내에 임의의 기준(pivot)값을 정하고 해당 피벗으로 집합을 기준으로 두개의 부분 집합으로 나눈다.
한쪽 부분에는 피벗값보다 작은값들만, 다른 한쪽은 큰값들만 넣는다. 안정성 보장 X
더 이상 쪼갤 부분 집합이 없을 때까지 각각의 부분 집합에 대해 피벗/쪼개기 재귀적으로 적용.
예시 :

코드 :
#include<iostream>
using namespace std;
#define ARRNUM 8
int N = ARRNUM;
int arr[] = { 8,15,5,9,3,12,1,6};
void Swap(int& A, int& B)
{
int Temp = A;
A = B;
B = Temp;
}
int Partition( int left, int right)
{
int pivot = arr[right]; //맨 오른쪽을 피봇 선정
int i = (left - 1);
for (int j = left; j <= right-1; j++)
{
if (arr[j] <= pivot) //배열 순회하며 피봇이랑 같거나 작은 값 탐색
{
i++; //i 인덱스 위치와 교체
Swap(arr[i], arr[j]);
}
}
//다 찾고 맨오른쪽에 있던 피봇값과 교체
Swap(arr[i + 1], arr[right]);
return (i + 1); // 리턴값 기준으로 왼쪽은 리턴인덱스보다 작고 오른쪽은 큰값들
}
void Quick(int L, int R)
{
if (L < R)
{
int p = Partition(L, R); //한번 피봇으로 선정된 값 기준으로
Quick(L, p - 1); //피봇 기준 왼쪽 다시 정렬
Quick(p + 1, R); //피봇 기준 오른쪽 다시 정렬
}
}
int main() {
Quick(0, N - 1);
for (int i = 0; i < N; i++)
{
cout << arr[i] << endl;
}
return 0;
}버전 2
#include<iostream>
using namespace std;
#define ARRNUM 8
int N = ARRNUM;
int arr[] = { 2,15,5,9,3,12,20,6 };
void Swap(int& A, int& B)
{
int Temp = A;
A = B;
B = Temp;
}
void QuickSort(int left, int right)
{
int pivot = arr[(left+right)/2]; //피봇 중심 선정
int startIndex = left;
int endIndex = right;
while (startIndex <= endIndex) //startIndex가 endIndex보다 높아질떄까지 while
{
while (arr[startIndex] < pivot) //피벗보다 왼쪽에서 피벗보다 큰값 찾기
{
++startIndex;
}
while (arr[endIndex] > pivot) //피벗보다 오른쪽에서 피벗보다 작은값 찾기
{
--endIndex;
}
if (startIndex <= endIndex) //그렇게 찾아진 왼쪽 오른쪽 값을 서로 swap
{
Swap(arr[startIndex], arr[endIndex]);
++startIndex;
--endIndex;
}
}
if (left < endIndex) //피벗기준 왼쪽 smaller들 정렬
{
QuickSort(left, endIndex);
}
if (startIndex < right)//피벗기준 오른쪽 bigger들 정렬
{
QuickSort(startIndex, right);
}
}
int main() {
QuickSort(0, N - 1);
for (int i = 0; i < N; i++)
{
cout << arr[i] << endl;
}
return 0;
}
- 병합정렬과 마찬가지로 분할 정복법 사용(Divide-And-Conquer)
- 범위, 기준, 비교, 스왑으로 순서
- 빅오 표기(시간복잡도)
average,best동일
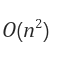
worst
C표준 라이브러리 - 퀵정렬 qsort() 함수
#include using namespace std; int Compare(const void*_elem1, const void*_elem2) { int * elem1 = (int*)_elem1; int * elem2 = (int*)_elem2; if (*elem1 > *elem2) return 1; else if (*elem1 < *elem2) ret..
hyo-ue4study.tistory.com
7. 기수 정렬(Radix Sort)
방법 : 낮은 자리수부터 비교해가며 정렬한다. 비교연산을 하지 않아 빠르지만, 또 다른 메모리 공간을 필요하다는게 단점.기수정렬은 낮은 자리수부터 비교하여 정렬해 간다는 것을 기본 개념으로 하는 정렬 알고리즘입니다. 기수정렬은 비교 연산을 하지 않으며 정렬 속도가 빠르지만 데이터 전체 크기에 기수 테이블의 크기만한 메모리가 더 필요합니다.
예시 :

코드 :
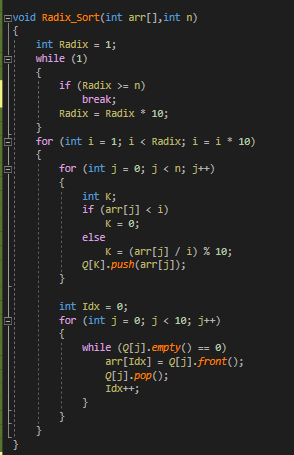
- 빅오 표기(시간복잡도)
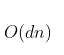
d는 자리수
'자 & 알 > 알고리즘' 카테고리의 다른 글
| [알고리즘 ] 동적 계획 법 (Dynamic Programming/DP) (0) | 2023.04.18 |
|---|---|
| [알고리즘] stable sort 와 unstable sort (2) | 2023.04.10 |
| [알고리즘] 길찾기 알고리즘(A* Algorithm) 구현(C++/UE4) (1) | 2021.04.08 |
| [알고리즘] [다익스트라 알고리즘]과 [A* 알고리즘] 그리고 [플로이드와샬 알고리즘] (0) | 2021.03.30 |
| [알고리즘] 플로이드 와샬(Floyd Warshall) 알고리즘이란? / C++ (0) | 2021.03.30 |

