
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 정렬
- moreeffectiveC++
- 비동기호출방법
- map
- 정렬알고리즘
- 선택정렬
- UE_LOG
- 프로그래머스
- C++최적화
- enumasByue
- 자료구조
- C++
- 데이터애셋
- UELOG
- UE4 커스텀로그
- 강참조
- stl
- 스마트포인터
- 구조적 바인딩
- dataasset
- unorder_map
- 알고리즘
- 람다
- 크리티컬섹션
- BFS
- 델리게이트
- UML관련
- 언리얼가비지컬렉터
- 약참조
- 애셋로드
- Today
- Total
기억을 위한 기록들
[UE] 게임스레드와 렌더스레드에 관하여 본문
UE에서는 전체 렌더러는 게임 스레드에 한 두 프레임 뒤쳐지는 별도의 스레드에서 작동
(렌더 스레드가 N 프레임일때 게임 스레드 N+1 일수 있음.)
렌더링 처리를 할 때 모든 메모리 읽기 쓰기의 스레드 안전성뿐만 아니라 그 행위의 결정론적 특성을 세심히 고려해야함. 함수적 행위가 두 스레드간의 실행 속도 차이에 따라 달라지는 경우를 경쟁(race) 조건이라 함.
경쟁 조건은 보통 재현하기가 매우 어렵기 때문에 피하는 것이 중요한데, 속도차이 때문에 기계, 플랫폼, 디버거, 환경설정에 따라 달라질 수 있기 때문입니다. 이러한 유형의 버그는 거의 디버깅이 불가능하여, 일반적으로 재현 가능한 버그에 비해 고치는 데 10 배 정도의 시간이 걸립니다.
경쟁 조건 / 스레딩 버그의 간단한 예제는 이렇습니다.
/** 씬에 컴포넌트가 등록될 때 FStaticMeshSceneProxy 가 게임 스레드에서 호출됩니다. */
FStaticMeshSceneProxy::FStaticMeshSceneProxy(UStaticMeshComponent* InComponent):
FPrimitiveSceneProxy(...),
Owner(InComponent->GetOwner()) <======== 주: AActor 포인터가 캐시됩니다.
...
/** 렌더러가 씬에 패스 작업중일 때 렌더링 스레드에서 DrawDynamicElements 가 호출됩니다. */
void FStaticMeshSceneProxy::DrawDynamicElements(...)
{
if (Owner->AnyProperty) <========== 경쟁 조건 발생! 게임 스레드가 모든 AActor / UObject 상태를 소유중이고,
// 언제든 쓰기가 가능합니다. 심지어 UObject 가 가비지 콜렉팅 되기라도 하면 크래시가 날 수도 있습니다.
// 이 프록시에서 AnyProperty 값을 미러링하는 것으로 안전하게 처리할 수 있습니다.
}개발 접근법
경쟁 조건을 확실히 찾아낼 수 있는 테스트 방법은 없다.
확실히 알아둬야 할 부분은, 추측 검사법이나 소급식 버그 수정법으로는 안정적인 스레디드 코드를 만들 수 없다는 점입니다.
가장 좋은 접근법은 게임 스레드와 렌더링 스레드의 상호작용 방식을 완전히 이해한 다음 결정론적인 부분을 확실히 할 수 있는 메커니즘을 사용하는 것.
모든 상호작용을 결정론적으로 만들게 될 이벤트의 순서를 확실히 설명할 수 있을 수준으로 알고있지 않고서야, 거의 반드시 경쟁 조건(Race)이 나타나게 될 것입니다.
스레드 전용 데이터 구조체
그때문에 누가 무엇을 변경할 수 있는지 명확해지도록 데이터를 각기 다른 스레드에 '소유된' 별도의 구조체에 저장하는 것이 좋습니다. 이 부분은 함수에도 마찬가지입니다.
항상 같은 스레드에서 각 함수를 호출하는 것이 최선이며, 그렇지 않으면 일이 정말 복잡해집니다.
Unreal Engine 대부분이 이런 식으로 구성되어 있는데, UPrimitiveComponent 를 예로 들자면 렌더링, 그림자 드리우기, 별도의 표시여부 상태 등을 가질 수 있는 것의 베이스 게임 스레드 클래스입니다. 렌더링 스레드는 절대 UPrimitiveComponent 의 메모리를 직접 건드릴 수 없는데, 게임 스레드가 어느때고 그 멤버에 쓰는 중일 것이기 때문입니다. 렌더링 스레드는 이러한 함수성을 나타내는 별도의 클래스, FPrimitiveSceneProxy 가 있습니다. 게임 스레드는 FPrimitiveSceneProxy 가 생성 및 등록된 이후에는 그 메모리의 멤버를 절대 건드릴 수 없습니다.
UActorComponent::RegisterComponent 는 씬에 컴포넌트를 추가한 다음 FPrimitiveSceneProxy 를 만들어 렌더러에 보이도록 만듭니다. 컴포넌트가 등록되고 나면 보이는 경우 필요한 모든 패스마다 FPrimitiveSceneProxy::DrawDynamicElements 를 호출시킵니다.
퍼포먼스 고려사항
매 틱 끝마다 게임 스레드는 렌더링 스레드가 한 두 프레임 정도 바짝 쫓아올 때까지 블록 상태로 대기합니다. 렌더링 스레드가 너무 많이 뒤쳐져있기 때문에, 게임플레이 도중 렌더링 스레드가 완전히 따라잡을 때까지 게임 스레드를 블록시킨 다는 것은 절대 있을 수 없는 일. 로드 도중 또는 개별 오브젝트의 GC 도중의 블록 역시도 안좋은 생각인데, Unreal Engine 는 비동기 스트리밍 레벨을 지원하기 때문.
블록 현상을 피하기 위한 여러가지 작업용 비동기 메커니즘이 있습니다.
스레드 상호 통신 7가지
1. 비동기
두 스레드 사이의 주된 통신 메서드는
ENQUEUE_UNIQUE_RENDER_COMMAND(...)매크로를 통하는 것입니다. 매크로에 입력한 코드가 들어있는 가상 Execute 함수를 포함해서 로컬 클래스를 생성해 주는 매크로입니다. 게임 스레드가 렌더링 명령 대기열(queue)에 명령을 삽입하면, 렌더링 스레드가 그 근처에 도달했을 때 Execute 함수를 호출합니다.
FRenderCommandFence 는 게임 스레드상에서 렌더링 스레드의 진행상황을 편리하게 추적할 수 있는 메서드를 제공
게임 스레드에서 FRenderCommandFence::BeginFence 를 호출하여 펜스를 시작합니다.
그러면 게임 스레드는 FRenderCommandFence::Wait 를 호출하여 렌더링 스레드가 펜스를 처리할 때까지 블록시키거나, 아니면 GetNumPendingFences 를 검사해서 렌더링 스레드의 진행상황을 확인할 수도 있습니다. GetNumPendingFences 가 0 을 반환하면 렌더링 스레드가 펜스 처리를 완료한 것입니다.
2. 블로킹
렌더링 스레드가 따라잡을 때까지 게임 스레드를 블록시키는 표준적인 메서드는 FlushRenderingCommands 입니다. 렌더링 스레드에 의해 접근되고 있는 메모리를 변경하는 오프라인 (에디터) 작업에 유용.
3. 렌더링 리소스
FRenderResource 는 기본적인 렌더링 리소스 인터페이스를 제공하며, 초기화(initialization) 및 해제(releasing)용 후크를 제공. FRenderResource 에서 파생되는 것들은 (FVertexBuffer, FIndexBuffer 등) 렌더링이나 해제에 사용되기 전 초기화를 시켜줘야 삭제가 가능합니다. FRenderResource::InitResource 는 렌더링 스레드에서만 호출 가능하므로, 게임 스레드에서 FRenderResource::InitResource 호출을 위한 렌더링 명령을 대기열 등록(enqueue)시키기 위해 호출 가능한 헬퍼 함수 (BeginInitResource) 가 있습니다. RHI 함수는 (디바이스, 뷰포트 생성 등의 몇 가지 예외를 제외하고) 렌더링 스레드에서만 호출 가능합니다.
4. UObject 및 가비지 컬렉션
가비지 컬렉션(GC)은 게임 스레드에서 발생하여 UObject 상에서 작동됩니다. 렌더링 스레드에서 UObject 를 가리키는 명령을 처리하는 와중에 게임 스레드에서 그 오브젝트를 삭제할 수가 있습니다. 그렇기 때문에 렌더링 스레드에서 UObject 를 더이상 가리키지 않는다는 것이 확실한 상태에서만 지울 수 있도록 하는 메커니즘이 확보되지 않고서야 UObject 포인터에 대한 레퍼런스를 절대 해제해서는 안될 것입니다. UPrimitiveComponent 를 예로 들면, DetachFence 라는 FRenderCommandFence 를 사용하여 렌더링 스레드가 detach 명령 처리를 끝낼 때까지 GC 가 UObject 를 삭제하지 못하도록 막는 것입니다.
5. 게임 스레드 FRenderResource 처리
게임 스레드와 렌더링 스레드 리소스 상호작용간에는 고려해야 할 시나리오가 두 가지 있는데, (인덱스 버퍼처럼 로드시 또는 에디터에서만 변경되는) 정적인 리소스의 경우와, 게임 스레드 시뮬레이션의 최신 결과로 매 프레임마다 업데이트시켜줘야 하는 동적인 리소스의 경우입니다.
6. 정적인 리소스
Unreal Engine 에서의 정적인 리소스 상호작용 처리방식을, USkeletalMesh 를 예로 들어 설명하겠습니다.
- 로드시 USkeletalMesh::PostLoad 가 호출되어, InitResources 를 호출합니다. 여기에 인덱스 버퍼같은 정적인 FRenderResource 에 대해 BeginInitResource 를 호출합니다. BeginInitResource 는 FRenderResource::InitResource 호출을 위해 렌더링 명령을 대기열에 등록시킵니다.

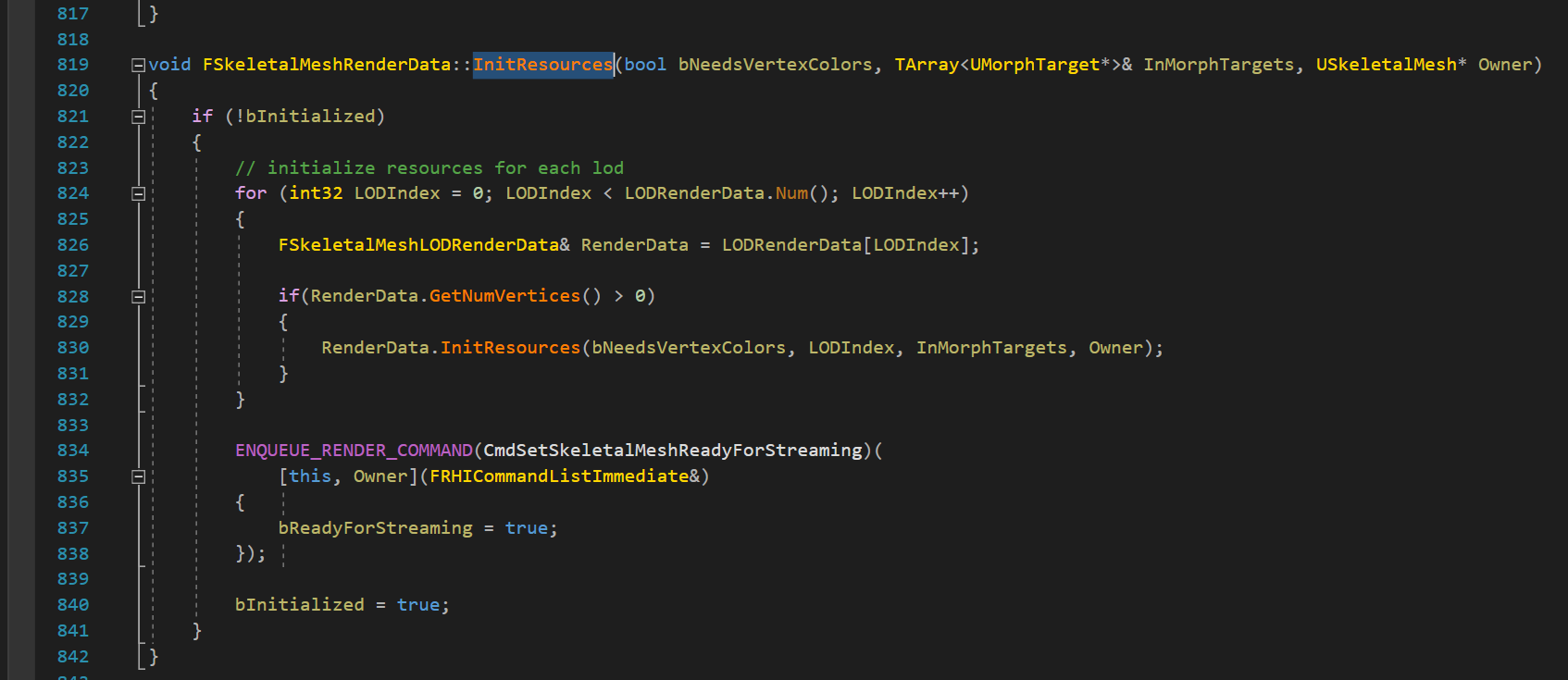
- 이 시점에서 게임 스레드는 인덱스 버퍼 메모리 소유권을 되찾기 위한 작업을 해 주기 전까지 더이상 그 메모리 변경이 불가능합니다.
- USkeletalMesh 의 인덱스 버퍼로 렌더링을 시작하는 컴포넌트를 등록합니다.
- 일정 (레벨 언로드 또는 참조 해제) 시점에서 가비지 컬렉션(GC)이 더이상 참조되지 않는 컴포넌트를 확인하여 컴포넌트를 detach 시킵니다. 참고로 이 때, 게임 스레드는 인덱스 버퍼 메모리를 삭제할 수 없는데, 렌더링 스레드에서 detach 처리가 끝나지 않아 여전히 인덱스 버퍼로 렌더링중일 수 있기 때문입니다.
- GC 는 USkeletalMesh::BeginDestroy 를 호출하는데, 이는 게임 스레드 오브젝트가 렌더링 리소스를 해제시키기 위한 명령을 대기열에 등록시킬 수 있는 기회이므로, BeginReleaseResource(&IndexBuffer); 를 합니다. 게임 스레드는 여전히 인덱스 버퍼 메모리를 삭제할 수 없는데, 렌더링 스레드가 아직 해제 처리를 마치지 못했을 수가 있기 때문입니다. 렌더링 스레드가 따라잡을 때까지 게임 스레드를 블록시킬 수는 있지만, 버벅임이 생기고 느려질 수 있으니 비동기적인 방법을 사용하겠습니다. 렌더링 스레드의 해제 명령 처리 진행상황을 추적하기 위해 펜스를 초기화시킵니다.
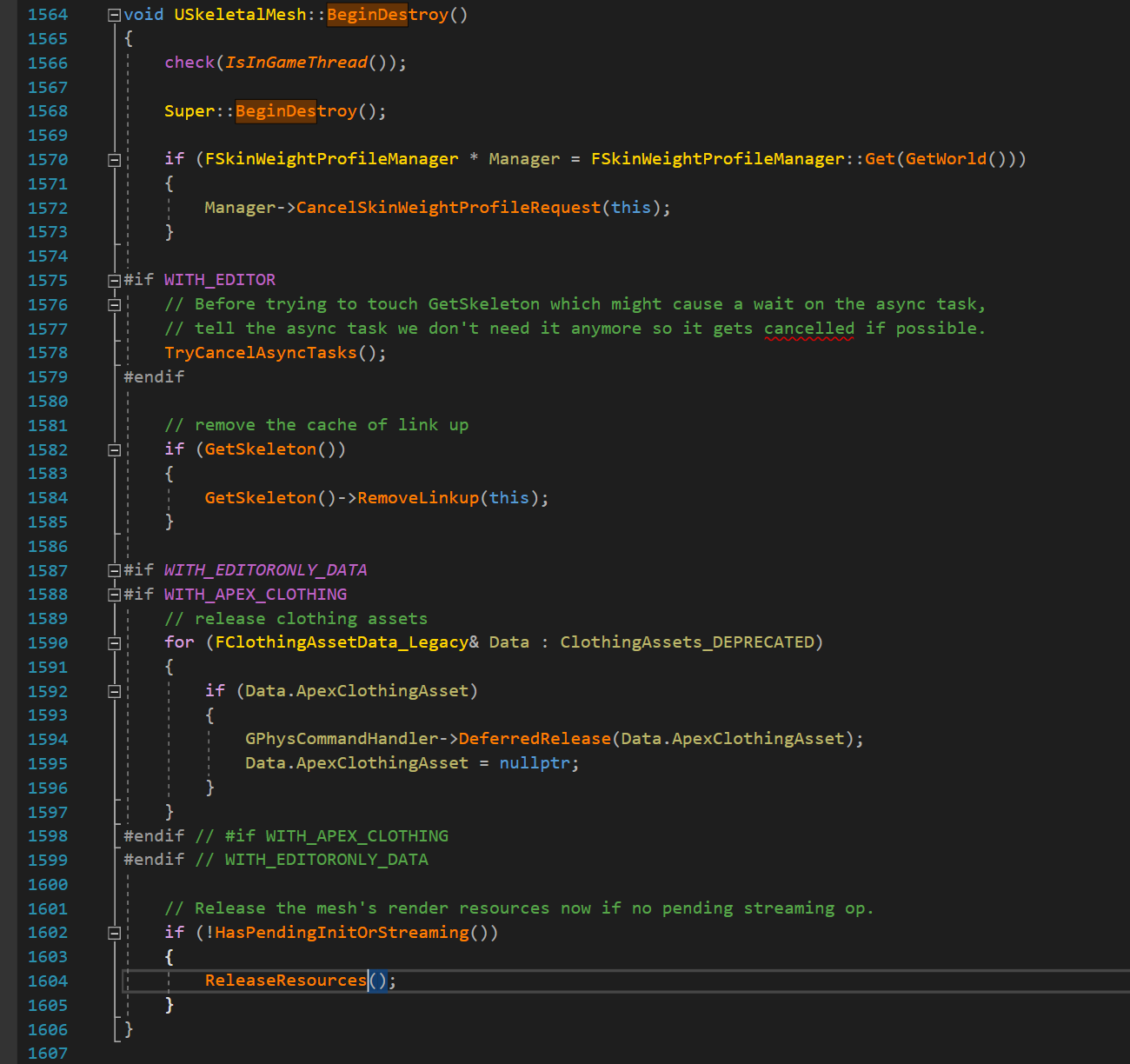
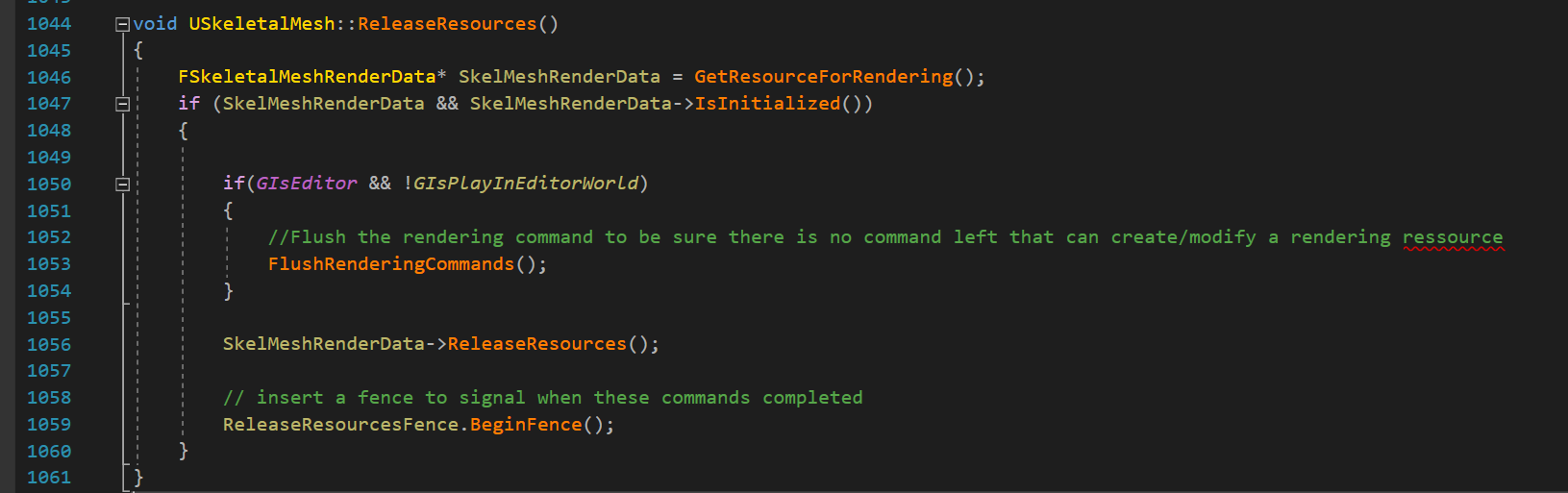
- GC 가 USkeletalMesh::IsReadyForFinishDestroy 를 호출, 이 함수가 True 를 반환할 때까지 UObject 는 소멸되지 않습니다. 함수가 True 를 반환하는 것은 오로지 렌더링 스레드가 펜스를 통과했을 경우만인데, 그렇다는 것은 게임 스레드에서 인덱스 버퍼 메모리를 안전하게 지울 수 있다는 뜻입니다.
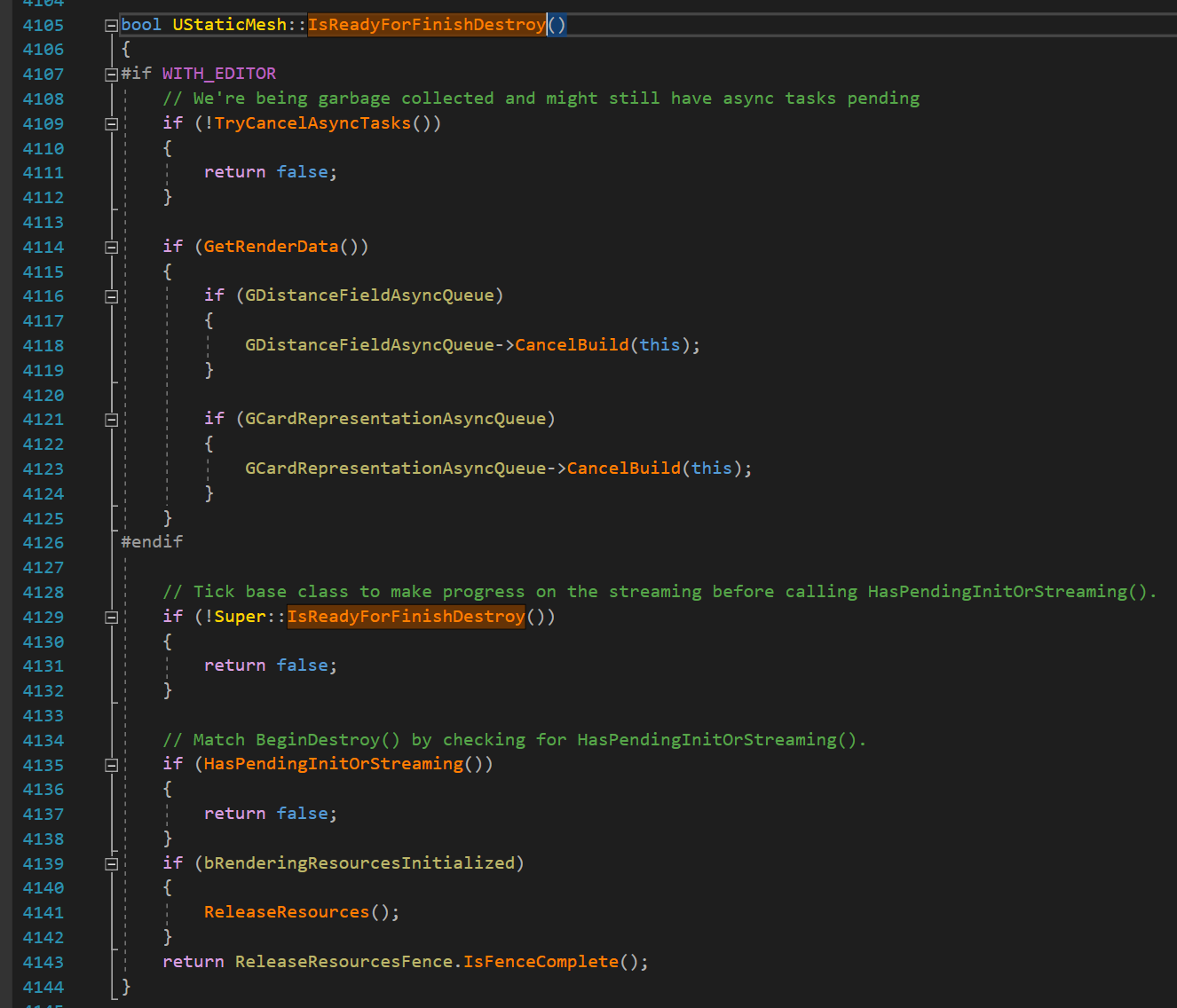
- GC 가 마지막으로 중앙 위치에서 메모리 해제에 사용할 수 있는 UObject::FinishDestroy 를 호출합니다. 인덱스 버퍼의 경우, 그 메모리가 해제되는 것은 USkeletalMesh 소멸자가 FRawStaticIndexBuffer 를 호출할 때이며, FRawStaticIndexBuffer 에서는 인덱스 버퍼 메모리를 담고 있는 TArray 의 소멸자를 호출하므로 메모리를 해제시킵니다.
이 메커니즘은 효과가 좋은데, (어느 스레드도 블로킹하지 않고, 초기화가 매 프레임 필요한지 검사할 필요 없이 중앙 위치에서 초기화가 이루어지기 때문에) 효율적이고 결정론적이기 때문입니다.
7. 동적인 리소스
매 프레임 게임 스레드 애니메이션에 의해 생성되는 스켈레탈 메시 본 트랜스폼이 동적인 리소스 업데이트의 좋은 예입니다. 각 애니메이션 업데이트 이후 게임 스레드에서 트랜스폼을 구하여, 셰이더 상수로 설정 가능한 렌더링 스레드 상의 배열에 넣는 것이 목표입니다. 매 프레임마다 인덱스 또는 버텍스 버퍼를 업데이트한대도 똑같이 적용될 것입니다. 연산 순서는 이렇습니다:
- USkinnedMeshComponent::CreateRenderState_Concurrent 가 USkinnedMeshComponent::MeshObject 를 할당합니다. 이 시점에서 게임 스레드는 MeshObject 포인터에만 쓰기 가능하며, FSkeletalMeshObject 메모리에는 쓸 수 없습니다.
- 컴포넌트의 동작을 프레임당 최소 한 번 업데이트하기 위해 USkinnedMeshComponent::UpdateTransform 이 호출됩니다. GPU 스키닝의 경우 여기서 FSkeletalMeshObjectGPUSkin::Update 를 호출합니다. 이 시점에서 게임 스레드상에 최신의 트랜스폼 정보가 있으므로 렌더링 스레드에 넘겨줘야 합니다. 그 작업은 먼저 히프에 (FDynamicSkelMeshObjectData) 먼저 메모리를 할당한 다음, 본 트랜스폼을 그 속에 복사하고서, 이 사본을 ENQUEUE_UNIQUE_RENDER_COMMAND_TWOPARAMETER 를 사용하여 렌더링 스레드에 전달해 주는 것으로 이루어집니다. 렌더링 스레드는 이제 사본을 소유하고 그 삭제를 담당합니다. ENQUEUE_UNIQUE_RENDER_COMMAND_TWOPARAMETER 매크로에는 트랜스폼을 최종 목적지에 복사하여 셰이더 상수로 설정가능하도록 하는 코드가 들어있습니다. 버텍스 위치를 업데이트하는 경우 버텍스 버퍼를 고정 및 업데이트시키는 곳이 바로 이 곳입니다.
- 일정 시점에서 컴포넌트가 detach 됩니다. 게임 스레드는 모든 동적인 FRenderResource 해제를 위한 렌더링 명령을 큐에 등록하고, 이제 MeshObject 포인터를 NULL 로 설정 가능하지만, 실제 메모리는 여전히 렌더링 스레드에 참조되고 있어 삭제가 불가능합니다. 여기서 지연(deferred) 삭제 메커니즘이 등장합니다. FDeferredCleanupInterface 에서 파생된 클래스는 스레드 안전성이 있는 비동기 방식으로 삭제 가능합니다. FSkeletalMeshObject 는 이 인터페이스를 구현합니다. 게임 스레드는 FSkeletalMeshObject 의 지연 삭제 명령을 시작하고 싶기에 BeginCleanup(MeshObject) 를 호출합니다. 삭제하기 안전하다 싶은 시점에서 청소 작업이 완료되면, 메모리는 결국 삭제될 것입니다.
상태 업데이트 대 렌더링할 씬 횡단
업데이트와 렌더링 작업이 별개인 시스템을 개발할 때는 DrawDynamicElements 에 그 둘을 합치고자 하는 유혹을 받습니다만, 디자인적으로 잘못된 선택입니다. 렌더링 횡단(traverse)에서 업데이트를 분리시키는 것이 더 나은 해법입니다. 예를 들면 게임 스레드 틱 안에서 업데이트 명령을 대기열 등록시키는 것입니다.
DrawDynamicElements 는 프리미티브 컴포넌트의 엘리먼트를 그리기 위해 하이 레벨 렌더링 코드에 의해 호출됩니다. 하이 레벨 코드는 변경되는 RHI 상태가 없다고, 셰이딩 패스 / 뷰 갯수 / 씬의 씬 캡처에 따라 매 프레임 필요한 만큼 얼마든지 DrawDynamicElements 를 호출할 수 있다고, 가정을 합니다.
DrawDynamicElements 호출이 가능은 하지만, 그렇게 되면 내재된 그리기 정책이 여러가지 이유로 그리기 결과를 버립니다 (예를 들어 뎁스 패스 도중 제출된 반투명 FMeshElement 는 버려질 것입니다). 프리미티브 컴포넌트가 실제로 보이지 않는 경우, 오클루전 시스템에서 사용중인 휴리스틱에 따라 DrawDynamicElements 를 실제 호출할 수도 하지 않을 수도 있습니다.
이 모든 요인이 프레임당 한 번 일어날 수 있는 상태 업데이트와 충돌할 수 있습니다.
더 나은 해법은 렌더링 횡단에서 업데이트를 분리하는 것입니다. 게임 스레드 틱은 업데이트 명령 수행을 위한 렌더링 명령을 대기열에 등록시킬 수 있습니다. 용례에 적합한 경우 프리미티브 씬 정보의 LastRenderTime 을 사용하여, 렌더링 명령은 표시여부에 따라 선택적으로 업데이트를 생략할 수 있습니다. 업데이트 명령이 이런 식으로 별도 대기열 등록되면, 다른 렌더 타깃 설정을 포함해서 어떤 RHI 함수도 사용 가능합니다.
상태 캐시 작업은 (업데이트와는 반대로) 이 규칙에 예외입니다. 스테이트 캐시는 최적화의 일환으로 렌더링 횡단의 중간 결과를 저장하는 것입니다. 횡단에 밀접하게 묶여있고, RHI 상태를 변경하지도 않으므로, (캐시 시점만 올바르게 결정되는 한) 앞서 말한 단점에 영향받지 않습니다.
기반 참고 자료 :
https://docs.unrealengine.com/5.0/ko/threaded-rendering-in-unreal-engine/
스레디드 렌더링
스레디드 렌더러 작업을 하는 그래픽 프로그래머를 위한 정보입니다.
docs.unrealengine.com
'UnrealEngine' 카테고리의 다른 글
| [UnrealEngine] 데이터 테이블(DataTable) vs 데이터 애셋(Data Asset) (0) | 2023.12.26 |
|---|---|
| ue4 caps lock 상태 가져오기 (0) | 2022.12.05 |
| 언리얼 빌드 커맨드 저장용 (0) | 2022.09.21 |
| [UE4]모듈에 관하여 (0) | 2022.04.17 |
| [UE4]플러그인이란? (0) | 2022.04.17 |
